Pharmacovigilance plays a crucial role in ensuring public safety by monitoring, identifying, and assessing potential drug-related risks and adverse events after market authorization. With the rapid expansion of available health data and evolving needs of the pharmaceutical industry, there is a growing demand for advanced techniques to manage, analyze, and interpret this data to improve safety surveillance. Signal analytics technology has emerged as a promising solution to meet these demands and strengthen pharmacovigilance systems.
By leveraging data-driven methodologies and machine learning algorithms, signal analytics technology in pharmacovigilance is transforming the way safety signals are detected, managed, and evaluated, thus enhancing the efficiency and effectiveness of drug safety processes. These advances provide researchers and regulators with novel tools for acquiring and processing diverse sets of data to identify previously unknown drug interactions, generate hypotheses, and anticipate potential hazards to public health, ensuring that a proactive approach is maintained in drug safety vigilance.
Key Takeaways
- Signal analytics technology is revolutionizing pharmacovigilance through data-driven methodologies and machine learning algorithms.
- Advanced signal detection techniques contribute to more efficient and proactive identification and management of drug-related risks.
- Diverse data sources and technological advancements enable researchers and regulators to better anticipate potential hazards to public health.
The Role of Signal Analytics in Pharmacovigilance
Defining Signal and Its Importance in PV
A signal in pharmacovigilance (PV) refers to information that suggests a new or previously unrecognized causal relationship between a drug and an adverse event. Signal detection and management play crucial roles in PV, as they contribute to ensuring the safety and efficacy of medicines. The primary goal of PV is to identify and assess potential signals in order to protect patients and improve public health. In this context, signal analytics refers to the application of various data analysis techniques and technologies for identifying, evaluating, and managing signals.
Evolution of Signal Detection and Management
Over the years, signal detection has evolved from manual, individual case assessments to sophisticated, data-driven approaches. Initially, PV professionals relied heavily on spontaneous reporting systems and manual review of individual case safety reports. However, with the growing volume of data and the increasing complexity of drug safety issues, automated and data-driven approaches have become more prominent. These technological advances include data mining techniques, artificial intelligence, and machine learning algorithms, which allow for more efficient and accurate identification of potential signals.
Signal management has also evolved in parallel with signal detection. Once a potential signal is identified, it must be assessed and managed appropriately. This involves evaluating the signal’s validity, its clinical relevance, and the potential impact on patient safety. Effective signal management enables prompt actions such as updating drug labels, disseminating risk communication materials, and, if necessary, initiating regulatory actions to protect patients and public health.
Impact on Patient Safety and Public Health
Signal analytics in pharmacovigilance has made a significant impact on patient safety and public health. By providing a more efficient and accurate means of identifying potential signals, it has allowed PV professionals to promptly respond to drug safety concerns and minimize the risks associated with medication use. Some key benefits of signal analytics include:
- Faster signal identification: Data-driven approaches enable more rapid detection of potential signals, which can lead to earlier interventions and improved patient safety.
- Reduced false signals: Advanced analytics techniques can help filter out false or irrelevant signals, which allows PV professionals to focus on the most critical safety issues.
- Improved decision-making: Through the use of data visualization tools and more sophisticated data analysis, PV professionals can make better-informed decisions regarding potential signals and their management.
- Enhanced collaboration: The use of centralized databases and advanced analytics platforms facilitates collaboration between PV professionals, regulatory authorities, and the pharmaceutical industry, which can result in more efficient and coordinated approaches to drug safety issues.
In conclusion, signal analytics plays a vital role in pharmacovigilance, contributing to the continued improvement of patient safety and public health. As technology continues to advance, it is expected that signal detection and management will become even more efficient and effective, further enhancing the ability to protect patients and maintain confidence in the safety of medicines.
Signal Detection Methodologies
Spontaneous Reporting Systems
Spontaneous reporting systems (SRS) play a crucial role in pharmacovigilance signal detection. These systems collect individual case reports of adverse events from healthcare professionals and patients. The primary purpose of SRS is to detect new, rare, or serious adverse events that were not identified during clinical trials. It is important to note that spontaneous reports can sometimes contain incomplete or inaccurate data, which may affect the signal detection process.
Data Mining Techniques
With the increasing availability of large-scale databases in pharmacovigilance, data mining techniques have become essential in detecting potential safety signals. These techniques can help identify patterns and trends from vast amounts of data, enabling the recognition of potential associations and risks. Some common data mining methods include disproportionality analysis, cluster analysis, and association rule mining.
Disproportionality analysis is a statistical method used to identify an unusually high frequency of specific drug-event combinations. This approach evaluates the reported adverse events and compares the observed frequency with the expected frequency, given a null hypothesis of no association.
Cluster analysis groups similar adverse events together, providing a way to detect patterns that may not be apparent when analyzing individual cases. This approach helps identify potential signals that share common features, such as clinical manifestations, time-to-onset, or demographic characteristics.
Association rule mining is another technique used in pharmacovigilance data analysis. This method identifies relationships between drug-event pairs, helping to uncover hidden relationships and potential safety signals.
Use of Algorithms and Machine Learning
As the complexity of pharmacovigilance data continues to grow, the use of algorithms and machine learning techniques has become more prevalent in signal detection. These approaches can help automate the identification of potential safety signals and reduce the time required for manual analysis.
One popular method is the application of neural networks in pharmacovigilance. Neural networks are computing systems inspired by the human brain, and they can be trained to recognize patterns and make predictions. By processing large amounts of data, neural networks can help identify unusual associations between drugs and adverse events, leading to the detection of potential safety signals.
Another technique is the use of machine learning algorithms, such as decision trees and support vector machines, to classify and predict adverse event outcomes. These algorithms can improve the accuracy and speed of signal detection by reducing the reliance on manual data analysis.
Overall, signal detection methodologies are continually evolving, with the incorporation of cutting-edge technologies offering additional insights into pharmacovigilance and drug safety. By leveraging spontaneous reporting systems, data mining techniques, and algorithm-based approaches, researchers can keep patient safety at the forefront of pharmaceutical development.
Data Sources and Collection
Databases and Individual Case Safety Reports
Pharmacovigilance heavily relies on databases and Individual Case Safety Reports (ICSRs) for gathering safety data. ICSRs are collected from healthcare professionals, patients, and other stakeholders through established reporting systems. These reports also include adverse events provided by regulatory authorities, such as the EMA, to enhance the analysis of safety information at a European level1. Additionally, global and national pharmacovigilance databases store a vast amount of information to facilitate signal detection, analysis, and interpretation.
Integration of Various Data Types
To improve accuracy and scope in detecting drug-drug interaction signals, different data sources must be integrated. The incorporation of both structured and unstructured data is necessary for a comprehensive overview of safety issues that might go unnoticed through manual analysis2. Some emerging sources include:
- Social media platforms, providing real-world data on patient experiences and potential adverse events.
- Pharmacoepidemiological studies, which offer information on drug utilization patterns and comparative safety assessments.
- Clinical trial data, contributing further knowledge on drug safety during pre-authorization phases.
Claims and Electronic Health Records
Claims data and Electronic Health Records (EHRs) serve as significant, yet heterogeneous, data sources in pharmacovigilance3. They include information such as:
- Diagnoses
- Procedures
- Prescriptions
The inclusion of data from general practitioners (GPs) and family pediatricians is especially beneficial. Claims and EHRs help monitor real-world drug safety, allowing for the identification and evaluation of potential signals in various healthcare settings.
In summary, the combination of diverse data sources, including databases, ICSRs, EHRs, and claims data, is essential for an effective signal detection and management system in pharmacovigilance. By embracing a data-driven approach, the industry can better assess the risk-benefit profile of drugs and promote public health.
Footnotes
- [HTML] [HTML] Signal detection in pharmacovigilance: a review of informatics-driven approaches for the discovery of drug-drug interaction signals in different data sources. ↩
- [HTML] [HTML] An open-source platform integrating emerging data sources to support multi-modal active pharmacovigilance. ↩
- From big data to smart data for pharmacovigilance: the role of healthcare databases and other emerging sources. ↩
Adverse Event Analysis and Validation
Standardizing Adverse Event Reporting
Pharmacovigilance relies on the accurate analysis of adverse events (AEs) to identify potential safety signals and ensure the safe use of pharmaceutical products. To streamline this process, it is essential to standardize adverse event reporting in a consistent and clear manner. Common frameworks, such as the Medical Dictionary for Regulatory Activities (MedDRA) and the World Health Organization (WHO) Adverse Reaction Terminology (ART), have been developed to classify and categorize adverse events effectively.
Standardized reporting allows for the easy comparison of data from different clinical trials, contributing to a more comprehensive understanding of the safety profile of a drug. In addition, standardization facilitates communication between regulators, healthcare professionals, and the pharmaceutical industry, ensuring that relevant information is shared and acted upon promptly.
Validation Processes and Causality Assessment
An essential component of adverse event analysis is the validation of reported events and causality assessment. The aim is to determine the likelihood that a given event is connected to the use of a particular drug. Factors to consider when assessing causality include:
- Temporal relationship: Did the event occur within a reasonable timeframe after the drug was administered?
- Biological plausibility: Could the drug reasonably cause the reported event based on its pharmacological properties?
- Previous evidence: Have similar events been reported with the same or related drugs in the past?
- Alternative explanations: Can the event be explained by other factors, such as underlying medical conditions or concomitant medication use?
These factors are used to generate a causality score, which can range from “unlikely” to “very likely” related to the drug. A higher causality score might prompt further investigation or action, such as regulatory warnings or recommendations for surveillance.
Signal Validation and Strength Assessment
Once potential safety signals have been identified, they must be validated and their strength assessed. Signal validation involves confirming that the observed association between a drug and an adverse event is genuine and not due to chance or bias. This can be achieved through various statistical techniques, such as disproportionality analysis, which compares the reporting rate of an event for a specific drug to the reporting rate in a broader database of adverse events.
Strength assessment evaluates the evidence supporting a safety signal, taking into account factors such as:
- Consistency: Is the signal present in multiple data sources or studies?
- Specificity: Is the signal unique to the drug in question, or do similar signals exist for other drugs in the same class?
- Quality of data: Are the reported adverse events well-documented and reliable?
A stronger signal may warrant more urgent action or closer monitoring, while a weak signal may be deprioritized or deemed coincidental. By meticulously analyzing, validating, and assessing adverse events, pharmacovigilance professionals can protect public health by detecting potential safety issues early and ensuring that timely and appropriate actions are taken.
Regulatory Framework and Guidelines
Pharmacovigilance is a crucial aspect of drug safety, and signal analytics technology plays an important role in the early detection of potential risks associated with medications. This section will discuss the regulatory framework and guidelines that govern signal analytics technology in pharmacovigilance.
Global Pharmacovigilance Regulations
The primary objective of global regulators is to ensure the safety and efficacy of medicinal products. Regulatory bodies such as the US Food and Drug Administration (FDA), European Medicines Agency (EMA), and World Health Organization (WHO) develop and enforce guidelines for pharmacovigilance in their respective regions:
- FDA: The US FDA is responsible for regulating drugs and medical devices in the United States. It provides guidance documents and safety reporting requirements for drug manufacturers and healthcare professionals through the FDA Adverse Event Reporting System (FAERS).
- EMA: The EMA is the regulatory body overseeing the pharmacovigilance processes within the European Union (EU). It manages EudraVigilance, the EU’s central database for the reporting and analysis of suspected adverse reactions to the medicinal products authorized in the region.
- WHO: The WHO, as an international organization, coordinates global pharmacovigilance efforts and contributes to the harmonization of safety monitoring strategies across countries. Its Program for International Drug Monitoring establishes global standards and supports the development of national pharmacovigilance centers.
Standards by FDA, EMA, and WHO
These regulatory agencies have developed specific guidelines and standards for signal analytics technology in pharmacovigilance:
- FDA: The FDA’s guidance documents include recommendations for good pharmacovigilance practices, pharmacovigilance inspections, and post-marketing safety reporting. It also offers guidelines on data mining and quantitative signal detection methods.
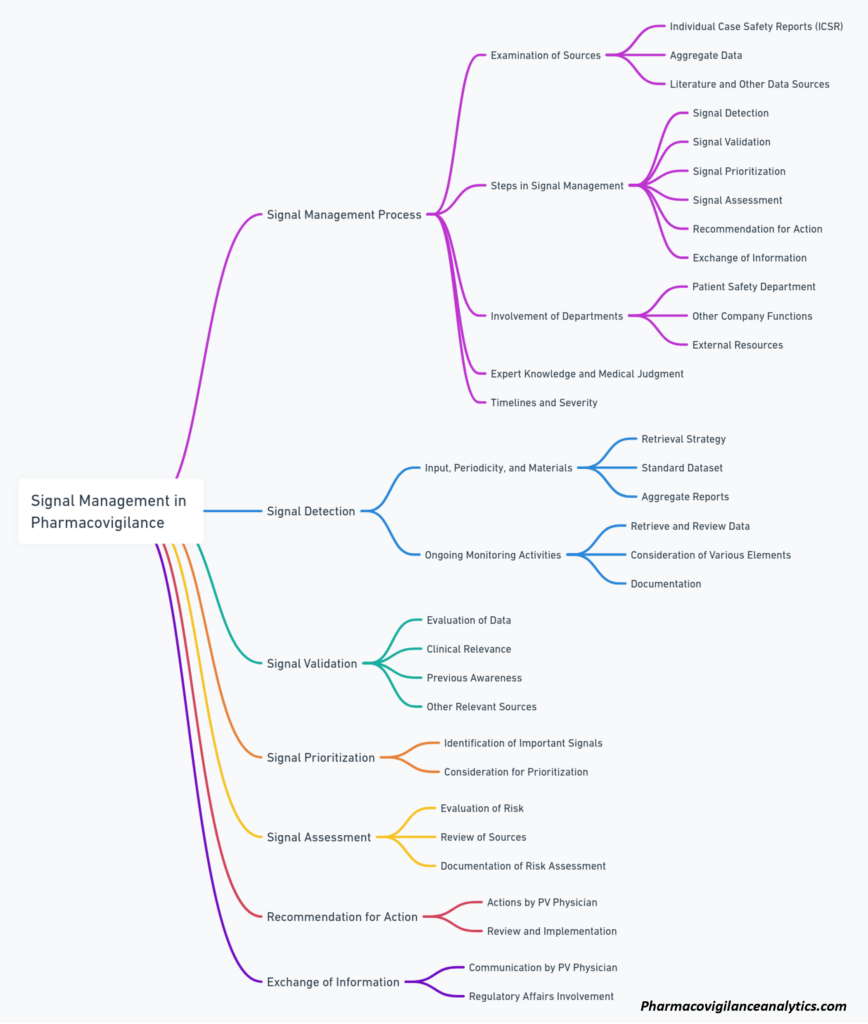
- EMA: As part of its good pharmacovigilance practices (GVP), the EMA has published Module IX on Signal Management. This document provides detailed guidance on the signal management process, which consists of signal detection, validation, analysis, prioritization, and reporting.
- WHO: The WHO encourages the use of signal detection and analysis methods in its guidelines for national pharmacovigilance systems. It also promotes collaboration between countries and information-sharing through the Uppsala Monitoring Centre (UMC), which maintains a global database of individual case safety reports called VigiBase.
Good Pharmacovigilance Practices
The concept of Good Pharmacovigilance Practices (GVP) encompasses the recommended procedures and systems designed to ensure the highest level of safety and efficacy monitoring for medicinal products. GVP assists in the identification of new safety information, helps manage identified risks, and refines the understanding of established risks.
Key GVP components include:
- Case management: Timely processing, assessment, and reporting of individual case safety reports from clinical trials and post-marketing surveillance.
- Signal management: Ongoing evaluation of aggregated safety data to identify potential signals of emerging safety concerns, using both quantitative (data mining) and qualitative (literature review) methods.
- Benefit-risk assessment: Continuous assessment of the balance between the therapeutic benefits and potential risks of a drug throughout its lifecycle, prompting appropriate risk minimization actions when necessary.
By adhering to GVP as mandated by the regulatory agencies, pharmaceutical companies and healthcare providers can ensure the highest levels of safety and efficacy for the patients they serve.
Implementation of Signal Management
Prioritization and Risk Assessment
In pharmacovigilance, signal management plays a crucial role in ensuring the safety and efficacy of medicinal products. The first step in this process is prioritizing potential safety signals based on their potential risks to public health. These signals may be derived from various sources, such as adverse event reports, clinical trial data, or post-marketing surveillance.
Risk assessment involves evaluating the strength of the evidence supporting a potential signal and considering the possible clinical consequences. The following factors are commonly considered:
- Frequency of the adverse event in the exposed population
- Severity of the event, including potential morbidity and mortality
- Likelihood of a causal relationship between the product and event
- Potential impact on patient populations, especially vulnerable groups
A structured approach for prioritization typically includes analysis of the available evidence, expert judgment, and utilization of decision-support tools.
Ongoing Monitoring and Mitigation Strategies
Once signals are prioritized, ongoing monitoring is crucial for ensuring the continuous evaluation of identified risks. This may include the use of various data sources, such as spontaneous reporting systems, electronic health records, or literature searches. The goal is to detect new information that could alter the understanding or management of a signal.
Based on the findings from ongoing monitoring, risk management strategies can be designed and implemented to minimize potential harms. These strategies may involve:
- Labeling updates to communicate new safety information
- Restrictions on the product’s indication, population, or dosing
- Educational initiatives aimed at increasing awareness among healthcare professionals and patients
- Post-marketing safety studies to gather additional data on the safety and effectiveness of the product
Communicating With Stakeholders
Effective communication with stakeholders is essential in signal management. This includes sharing information with regulatory authorities, healthcare professionals, patients, and the general public. Timely and transparent communication ensures that all parties are informed of the potential risks and benefits associated with medicinal products.
There are various channels for communication, such as:
- Periodic safety update reports submitted to regulatory authorities
- Prescriber and patient information materials, including package inserts or medication guides
- Safety alerts, warnings, or recalls issued by manufacturers or regulatory agencies
- Scientific publications and presentations at conferences or meetings
Through these channels, stakeholders are kept informed and can actively participate in risk minimization efforts, ultimately leading to improved public health outcomes.
Technological Advancements in Pharmacovigilance
Role of Artificial Intelligence and Big Data
In recent years, the integration of artificial intelligence (AI) and big data has significantly impacted pharmacovigilance. These technologies facilitate more efficient adverse event processing and signal detection by enabling the rapid analysis of large volumes of data. Additionally, AI and big data improve data quality and allow for better identification of potential safety concerns. Machine learning algorithms, a subset of AI, can identify patterns and associations within datasets, leading to new insights that may help in detecting and managing risks associated with drugs.
Advances in Automation for PV Systems
Automation has become an essential aspect of modern pharmacovigilance systems. By automating various processes, such as aggregate analysis and risk assessment, it becomes possible to improve the efficiency of the overall system. AI-powered automation helps to minimize human error, ensure data consistency, and reduce the time required to carry out complex tasks. This results in better decision-making and more accurate predictions, both of which are critical to the successful management of drug safety. Here are some examples of automation:
- Automating signal management to prioritize and track signals according to their importance and risk
- Streamlining the processing of individual case safety reports (ICSRs) to reduce manual effort and improve data quality
- Standardizing the definitions and analysis of signals for more consistent data handling across the board
Future of Signal Analytics
The future of signal analytics in pharmacovigilance looks promising, with new technologies continually emerging to enhance its capabilities. Innovations in areas such as natural language processing (NLP) and deep learning could further improve the detection and analysis of potential safety signals in drugs. Integration with other advances in technology, such as blockchain and Internet of Things (IoT), may also play a vital role in the development and evolution of signal analytics.
As these advancements unfold, there will be challenges and opportunities for pharmacovigilance professionals to navigate. Fostering collaborations between stakeholders, encouraging standardization, and embracing the potential of these technologies will be key to overcoming these challenges and maximizing the benefits that technological advancements bring to pharmacovigilance.
Challenges and Future Outlook
Handling Data Volume and Quality
The increasing volume and complexity of data in pharmacovigilance pose significant challenges for signal analytics. With the rapid growth of diverse data sources like social media, electronic health records, and patient registries, ensuring data quality becomes essential for meaningful analysis. Data standardization and integration are crucial steps to improve data quality, and organizations need to invest in robust data management systems to handle the growing volume.
To overcome these challenges, the future of signal analytics may involve harnessing advanced technologies like machine learning and natural language processing, which can help in filtering relevant information, detecting patterns, and reducing noise from large datasets. These technologies can also help automate data cleaning and validation processes, ultimately enhancing data quality for signal analysis.
Balancing Automation and Manual Assessment
While automation plays a crucial role in improving efficiency and reducing the burden on pharmacovigilance professionals, achieving the right balance between automation and manual assessment remains a challenge. Overdependence on automation can lead to missed signals or false positives, while excessive reliance on manual assessment can be resource-intensive and time-consuming.
A potential solution to this challenge lies in the development of hybrid systems that blend automation with human expertise. By leveraging the strengths of both approaches, these systems can help minimize errors and improve the overall effectiveness of signal analytics. In the future, user-friendly interfaces and appropriate training programs are expected to facilitate the seamless integration of these hybrid systems into pharmacovigilance workflows.
Evolving Regulatory and Ethical Landscape
The dynamic nature of the regulatory and ethical landscape poses its own set of challenges for signal analytics in pharmacovigilance. As regulations evolve, organizations must adapt their systems and processes accordingly to ensure compliance. For instance, the growing emphasis on patient privacy and data protection might require substantial changes in data management practices across the industry.
To stay ahead of the curve, organizations should maintain a proactive approach towards regulatory changes and foster collaborations with relevant stakeholders such as patients, healthcare professionals, and regulators. Investing in the continuous education and training of staff on regulatory guidelines can help organizations navigate the evolving landscape successfully.
In conclusion, the challenges mentioned above can be addressed through a blend of technology-driven innovations and human-centered approaches. By embracing advanced technologies, data management best practices, and collaborative efforts, the future of signal analytics in pharmacovigilance looks promising.
Frequently Asked Questions
How is technology leveraged for signal detection in clinical trials?
Technology plays a pivotal role in signal detection during clinical trials, particularly in the form of data mining algorithms. These algorithms analyze vast amounts of data collected from various sources, such as electronic health records, spontaneous reports, and literature reviews, to identify patterns or trends that may indicate a potential safety concern or adverse event related to a drug under investigation.
What tools are utilized for signal intelligence in pharmacovigilance practices?
Several software tools and platforms are employed in pharmacovigilance practices to facilitate signal intelligence. Some of these tools include quantitative data mining algorithms, artificial intelligence (AI) techniques, and machine learning models that help analyze the data set and identify potential safety signals. These tools also assist in the ongoing monitoring and management of risks associated with medications under investigation.
What constitutes a validated signal within the scope of pharmacovigilance?
A validated signal in pharmacovigilance is an identified potential safety concern that has undergone a thorough review and assessment process to determine its clinical significance and the likelihood that it may be related to a specific drug. A validated signal typically stems from a combination of different sources, such as spontaneous reports, clinical trials, and observational studies. Validation usually involves evaluating the strength, consistency, and specificity of the association between the drug and adverse event, as well as confounding factors and biases that may influence the observed relationship.
Can you explain the signal management process and its significance?
Signal management is a critical component of pharmacovigilance, aimed at the identification, evaluation, and communication of potential safety signals. The process begins with signal detection, which involves gathering and analyzing relevant data to identify possible drug-related safety concerns. Once a potential signal is identified, it undergoes validation and assessment to determine its clinical relevance and relationship with the drug. Finally, if a signal is confirmed, appropriate actions are taken, including risk communication, regulatory interventions, and updates to product labeling. The signal management process is essential for ensuring drug safety and minimizing potential risks associated with medication use.
What are the key differences between qualitative and quantitative signal detection methods?
Qualitative signal detection methods rely on the expert judgment of healthcare professionals and pharmacovigilance experts who review and evaluate reports and other information related to adverse events and drug safety. These methods often involve manual evaluation and interpretation of data, focusing on patterns, trends, and unexpected events. In contrast, quantitative signal detection methods employ statistical algorithms, data mining techniques, and other computational approaches to analyze large volumes of data and identify potential safety signals objectively. Quantitative methods often provide a more comprehensive and unbiased approach to signal detection compared to qualitative methods.
How does causality assessment factor into effective signal detection?
Causality assessment is an integral part of the signal detection process that aims to establish a potential causal relationship between an adverse event and a specific drug. It assists pharmacovigilance professionals in evaluating the likelihood that a drug may be responsible for an observed safety concern. Considerations for causality assessment include the temporal relationship between drug exposure and the adverse event, biological plausibility of the association, and any available supportive evidence, such as literature and similar cases. The process involves evaluating the strength, consistency, and specificity of the observed association while considering potential confounders and biases. Causality assessment supports effective signal detection by helping to distinguish possible drug-related safety issues from unrelated events or random coincidences.
 Signals of Disproportional Recording – Seriously?
Signals of Disproportional Recording – Seriously? Researchers are increasingly using Twitter to analyze what people are talking about at a given time point and over time. Among the multiple uses analysis of tweets can have, safety surveillance,
Researchers are increasingly using Twitter to analyze what people are talking about at a given time point and over time. Among the multiple uses analysis of tweets can have, safety surveillance,